
Abstract
Digital radiography is widely available and the standard modality in trauma imaging, often enabling to diagnose pediatric wrist fractures. However, image interpretation requires time-consuming specialized training. Due to astonishing progress in computer vision algorithms, automated fracture detection has become a topic of research interest. This paper presents the GRAZPEDWRI-DX dataset containing annotated pediatric trauma wrist radiographs of 6,091 patients, treated at the Department for Pediatric Surgery of the University Hospital Graz between 2008 and 2018. A total number of 10,643 studies (20,327 images) are made available, typically covering posteroanterior and lateral projections. The dataset is annotated with 74,459 image tags and features 67,771 labeled objects. We de-identified all radiographs and converted the DICOM pixel data to 16-Bit grayscale PNG images. The filenames and the accompanying text files provide basic patient information (age, sex). Several pediatric radiologists annotated dataset images by placing lines, bounding boxes, or polygons to mark pathologies like fractures or periosteal reactions. They also tagged general image characteristics. This dataset is publicly available to encourage computer vision research.
Measurement(s) | wrist fracture • pronator quadratus sign • AO classifiction • soft tissue swelling • metal implant • osteopenia • plaster cast • bone Lesion • subperiosteal bone formation |
Technology Type(s) | bone radiography |
Similar content being viewed by others

Background & Summary
Wrist radiographs are routinely acquired to assess injuries around the wrist, distal forearm and the carpal bones, in the acute setting as well as in follow-up. This is also true in the pediatric population. Distal radius and ulna fractures account for the majority of pediatric wrist injuries with an incidence peak in adolescence1,2,3.
Pediatric surgeons in training or emergency physicians often interpret trauma radiographs, sometimes without being backed-up by experienced pediatric radiologists. Even in developed countries, shortages of radiologists were reported, posing a risk to patient care4,5. In some parts of the world, access to specialist reporting is considerable restricted, if not unavailable6.
Studies indicated various amounts of diagnostic error in reading emergency X-rays, up to a percentage of 26%7,8,9,10. Further modalities like ultrasound, computed tomography (CT), and magnetic resonance imaging (MRI) can be helpful in case of uncertainties after completed clinical examination and radiography. They increase sensitivity and specificity. However, some fractures are even occult in these modalities11,12,13.
Computer vision algorithms were found to be useful in many medical fields, mainly when large amounts of data can be analyzed. First positive experiences with the detection of pathologies in trauma X-rays were recently published14,15,16,17. There is also a limited number of studies dealing with automated detection of wrist fractures in adults18,19,20,21,22. Computer vision applications typically rely on large numbers of training samples23,24. Large publicly available datasets enable researchers around the globe to compare their algorithms in a standardized way, yet, there are still limited options accessible to date25.
We present a comprehensively annotated pediatric wrist trauma radiography dataset (GRAZPEDWRI-DX) for machine learning. The acronym is composed of the terms “Graz”, “Pediatric”, “Wrist”, and “Digital X-ray”. The image collection is de-identified, distributed in an accessible file format (Portable Network Graphics, PNG, 16-bit grayscale), and publicly available. It is accompanied by various annotations as well as image and object tags established by human experts.
Methods
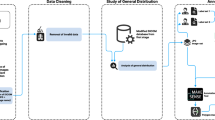
We constructed the GRAZPEDWRI-DX dataset from image data (pediatric wrist radiographs), natural language (report texts), and human expert annotations (bounding boxes, lines, polygons, and image tags). Annotations were established directly based onto the X-ray contents and with the aid of the corresponding free text reports, finally combined to the whole dataset. The whole process of dataset construction is presented as a flowchart in Fig. 1.

GRAZPEDWRI-DX dataset creation flowchart. Digital wrist radiographs were screened for eligibility in a pool of 20,711 images between 2008 and 2018. 384 images were excluded due to incorrect field of view that was not focused on the wrist. 20,327 images were included, tagged and annotated.
The project (No. EK 31-108 ex 18/19) was approved by the local ethics committee of the Medical University of Graz (IRB00002556). Requirement for oral or written patient consent was waived due to the retrospective project design. All study-related methods were conducted in accordance with the Declaration of Helsinki and all relevant guidelines and regulations.
Pediatric wrist radiographs
10,643 wrist radiography studies of 6,091 unique pediatric patients (mean age 10.9 years, range 0.2 to 19 years; 2,688 females, 3,402 males, 1 unknown) were retrieved as Digital Imaging and Communications in Medicine (DICOM) images from the local Picture Archiving and Communication System (PACS). DICOM is the standard medical image format which enables permanent storage and exchange between different modalities and institutions26,27. Apart from the pixel information, DICOM images contain meta data (DICOM header) that rely on tight rules. Some of the meta data are mandatory, while others are optional. The DICOM standard is updated regularly28. Since there are still some barriers with the use of DICOM, we decided to convert the images to the more widespread Portable Network Graphics (PNG) format. PNG images offer a lossless compression of the pixel data and can be stored in more than 8 Bit grayscale format. Radiography DICOMs typically contain 12-bit, sometimes 16-bit of grayscale information. DICOM images served as input and were read with the “pydicom” package29. The PNG format does not allow to store 12 bits per channel, so we normalized the grayscale values of all DICOMs to 16-bit, stretching the grayscale histogram from initially 0 to 4,095 (12-bit) to 0 to 65,535 (16-bit) with the “cv2” module. Afterwards, PNGs were saved to the hard disk.
Anonymization procedure
De-identification and image conversion procedure was performed in batch by a custom-coded Python script. PNGs do not allow to store meta data as a standard feature. To retain sufficient information for processing and analysis of the PNG images, we created the file names based onto DICOM header information. The first part of the filename was constructed from concatenated strings of “Blake2b”30 cryptographic hashes of “Institution” and “Patient ID”, afterwards hashed with “SHA-3-256”31. The resulting hash is the same for each individual patient. The second part of the file name consisted of the acquisition time’s Unix timestamp, subtracted by a 9-integer long hash of the “Patient ID”, keeping the original study intervals while irreversibly masking the original examination times. The series number and image number (zero-padded to two digits) represented the next part of the filename, which was followed by a region token, the laterality and projection, and finally sex and age (rounded to one decimal place). An example file name would be: „e07bd2cecaefda782adff762c134e7f26f1b72dec670cb6c36d42ce40e3e30fb_0020600143_01-01_WRI-L1_F010-3.png“. For this specific publication, we replaced the ascending patient hashes by continuous numbers from zero onwards, forced to four digits by zero-padding, and provided only full years of age. Moreover, we subtracted the Unix timestamps by an arbitrary number a second time, and replaced series number and image number by ascending study IDs, e.g. „4229_0020600143_02_WRI-L1_F010.png“, explained in Fig. 2.

Meaning of the individual file name parts. File names for images and annotations start with a four-digit patient number, followed by a hashed examination time, the ascending study number, the region code (all “WRI”), the laterality and projection code, and finally sex and age in years.
DICOM layers and overlays
Any additional layers or overlays in the original DICOM were irreversibly discarded during the image conversion and de-identification process.
Burned in annotations
After DICOM conversion including removal of the header information, PNG images can still contain identifying text in their pixel matrix, usually referred to as “Burned In Annotation”. These text passages, written into the image pixels can contain sensitive information about the patient, the radiological technologists or even the referring clinician. We found our DICOM headers routinely inaccurate regarding the presence of the “Burned In Annotation” attribute. Automated text-recognition methods based on the Tesseract optical character recognition software were not reliable enough to enable unvalidated masking of potentially sensitive information. We therefore screened all images manually and masked related images with black boxes in IrfanView (n = 97). In contrast to other publicly available datasets, we also masked radiographer abbreviations.
Image labeling
Board-certified pediatric radiologists (S.T., E.N., and E.S.) with experiences between 6 and 29 years in musculoskeletal radiology validated all images annotations performed on the Supervisely (Deep Systems LLC, Moscow, Russia) artificial intelligence online platform. A dedicated server hosted the web-based image database, allowing for collaborate labeling. Clients accessed the server with a web browser over the Internet. Apart from the mentioned validating radiologists, local radiologists, visiting colleagues, and medical students helped to progress the dataset with different shares of labeling times. All annotations were executed between March 2018 and February 2022.
The annotators manually placed objects with dedicated tools. Amongst others, we annotated fractures, metal implants, periosteal reactions, or bone lesions with bounding boxes, polygons, or lines. Image tags were manually set to represent features of each image, when appropriate. Collected objects (Fig. 3.) and image tags are listed in Tables 1 and 2.

Examples of different objects labelled by the human experts. In the first row from left to right: Fracture (bounding box), text (bounding box), periosteal reaction (polygon). In the second row from left to right: Pronator quadratus sign (bounding box), soft tissue swelling (bounding box), foreign body (bounding box). In the last row from left to right: Bone anomaly (bounding box), metal (bounding box), and axis (line). The middle radiograph in the first row shows a cast. The right images in the first and third row were tagged with osteopenia.
Pediatric radiology reports
All available radiology reports were manually read by the authors and classified either into fracture or no fracture. They served as basis for labeling fractures in the annotation period. The German natural language reports are not delivered together with the dataset as 1) we were not able assure full anonymity, 2) they might not be correctly linked to the corresponding image occasionally due to pooling of images of different date and/or body regions into single free text reports. However, we are willing to provide the reports for research purposes on request.
Data Records
Data are provided for download on Figshare (https://doi.org/10.6084/m9.figshare.14825193)32. We grant free access to the dataset, without the need for user registration. The dataset is distributed in ZIP archives with a total size of 15.2 Gigabytes (GB), containing its original folder structure displayed below.
Folder structure
We provide ready-to-use data in proprietary Supervisely project (“supervisely” folder) format, in PASCAL Visual Object Classes (VOC)33 format (“pascalvoc” folder), in YOLOv534 format (“yolov5” folder), as well as image tags in comma separated values (CSV) format. The whole project structure is shared by a ZIP file.
The root folder contains a CSV file (“dataset.csv”) with all filenames, basic patient information and image tags. The “notebooks” folder holds three pieces of code, one for previewing annotations, and one for splitting files based on two columns of a CSV file, and one image post-processing. They are released as Jupyter notebooks. The “images” folder contains all wrist radiographs in 16-bit PNG format. The “supervisely” folder has a single “meta.json” file and is structured into a “wrist” subfolder that consists of an “ann” subfolder with json annotations, and an empty “img” subfolder. This “img” subfolder needs to be populated from the “images” folder, if needed. The “pascalvoc” folder contains Extensible Markup Language (XML) data files for object detection. This folder also does not include image files, which need to be copied from the “images” folder, if necessary. Every annotation file is associated with a corresponding image file, featuring the same file basename and only variable file extension. The “yolov5” folder contains the labels as text files (TXT) in the dedicated YOLOv5 format. It comes with a “meta.yaml” file for basic settings and object mappings.
An annotated example study is provided in Fig. 4.

Fully tagged and labelled sample image viewed in the Supervisely online platform.
A total number of 67,771 objects were annotated in the dataset, splitting into the different categories as specifically detailed in Table 1. The “axis object consist of a two-point line along the main axis of the forearm bones. It is thought to be of help in automatically aligning the images. Bone anomalies (“boneanomaly”) are a heterogenous group of objects, representing bone pathologies from drill holes to Madelung’s deformities. Bone lesions (“bonelesion”) are bone tumors like osteomas. “foreignbody” refers to objects that label foreign bodies visible onto the image. The “fracture” object is used to annotate fractures. The “metal” object is used for internal or external metal implants. The annotators labeled periosteal reactions and callus under the label “periostealreaction” with polygons. The “pronatorsign” annotation resembles the specific radiological sign in terms of a swelling in the Musculus pronator quadratus region35,36. “softtissue” refers to an unspecific soft tissue swelling, usually due to trauma. “text” marks any text passage or single letters visible, most commonly laterality indicators “L” and “R”.
The annotators set 74,459 image tags in the 20,327 images. They included AO/OTA (“Arbeitsgemeinschaft für Osteosynthesefragen” /”Orthopaedic Trauma Association”) classifications (2018 version)37 in images with acute or subacute fractures, but not in healed or remodeled fractures. Images might contain AO classifications without a labeled fracture object (bounding box) in cases, where a fracture is known to be present but not clearly visualized in the respective projection. Table 2 lists and describes the different image classifications.
Top 5 most common AO classification ratings in the dataset are “23r-M/2.1” (n = 3,221), “23r-M/3.1; 23u-M/2.1” (n = 1,683), “23r-M/3.1; 23u-E/7” (n = 1,529), “23r-M/3.1; 23u-M/2.1” (n = 1,501), and “23-M/3.1” (n = 1,436), followed by a number of 102 further AO classifications or combinations that can be retrieved from the accompanying CSV file. Multiple fracture types within the same image are separated by semicolons.
Technical Validation
Image data is of high quality, delivered in full pixel resolution and complete grayscale spectrum. We did not apply any post-processing apart from histogram normalization (stretching) the usually 12-bit input spectrum to 16-bit due to meet PNG image format requirements. Note that there is no loss of information due this reversible procedure (Fig. 5.). Postprocessing is advised for typical computer vision tasks. We attached a script to optimize image contrast and convert the gray levels to 8 bits (“image_conversion.ipynb”).

Histograms of 6 sample images showing their grayscale spectra. Note that the full grayscale range was preserved when converting and normalizing the images. The relative number of pixels per grayscale level are normalized from 0 to 1 for display purposes.
All studies and their annotations were reviewed by experienced pediatric radiologists at least twice. Still, users need to consider inevitable inaccuracies, discrepancies, and errors in labeling due to the restricted diagnostic sensitivity of X-ray studies38,39. Images in question are tagged “diagnosis_uncertain” (n = 537, 2.64%). However, it must be kept in mind that annotation errors might not be confined to these images, but could be present within the whole dataset. Particularly AO classification codes are not always unambiguous. Images that are considered normal might contain occult fractures, while we believe that studies rated to be pathologic, are accurately tagged in the majority of cases.
We assessed “fracture” labeling agreement between the validating pediatric radiologists with intersection over union (IoU) measurements in a subsample of 100 randomly chosen overlapping images, resulting in a mean IoU 0.70 (1st percentile 0.22, 25th percentile 0.63, 50th percentile = median 0.73, 75th percentile 0.80, 99th percentile 0.94 for the blinded raters. An IoU of 1 resembles perfectly overlapping bounding boxes, while 0 would be no overlap at all. Thus, inter-rater bounding box agreement was moderate. However, the whole dataset was labeled in an iterative continuous fashion, where labels were little-by-little adjusted multiple times by different annotators. So labeling quality is considered more accurate than the IoU level alone might indicate.
Object detection performance
We trained a state-of-the-art neural network for object detection, namely YOLOv534 by randomly dividing the total dataset into a training set of 15,327 (of 20,327), and a validation set of 4,000 images. A Windows PC equipped with an Nvidia GeForce RTX 2060 SUPER (video memory size of 8,192 MB) ran 50 epochs of a COCO40 pre-trained “YOLOv5m” model with an input size of 640 pixels and a batch size of 16 samples. Standard hyperparameters were used. Python version was 3.9.5. Table 3 lists the results (precision, recall, mean average precision = mAP) achieved on the previously unseen test subset of 1,000 random samples. Fractures were detected with a precision of 0.917, a recall of 0.887, and a mAP of 0.933 at an IoU threshold of 0.5.
Usage Notes
The dataset is made freely available for any purpose. The data provided within this work are free to copy, share or redistribute in any medium or format. The data might be adapted, remixed, transformed, and built upon. The dataset is licensed under a Creative Commons “Attribution 4.0 International” license (CC BY 4.0) (https://creativecommons.org/licenses/by/4.0/). Users are prohibited to attempt re-identification of personal patient information.
Correct use of the dataset requires medical and radiological background knowledge, especially in interpreting obtained results and in drawing dataset-based conclusions. Potential labeling errors must be taken into consideration, as pointed out in the “Technical Validation” section. Our key aim in releasing this dataset is to encourage research in automated pediatric fracture detection. We believe that releasing the GRAZPEDWRI-DX dataset could improve research in this field.
Computer vision algorithms commonly rely on input images with 8 bits per channel for training and inference, particularly when using transfer learning bases on large image archives. The dataset contains a Python script that enables image conversion from the 16-bit source images to 8-bit samples (“image_conversion.ipynb”). It incorporates options to apply sharpening and contrast enhancing in terms of intensity rescaling and contrast limited adaptive histogram equalization (CLAHE), enabled by the Python “scikit-image (skimage)” package41.
The GRAZPEDWRI-DX dataset enables assessment of a variety of research questions around the injured pediatric wrist. To our knowledge, there are no related pediatric datasets publicly available. In adults, there is a limited number of musculoskeletal radiography collections available to the community. The Stanford University datasets MURA25 and LERA42 contain large numbers of samples but feature only binary labels, in terms of “normal” and “abnormal”. The MURA dataset consists of 14,863 studies (total of 40,561 multi-view radiographic images) from 12,173 patients25. The LERA dataset accumulated lower extremity radiographs of 182 patients42. Both lack comprehensive labeling that we provide within the current dataset.
We might release further revisions of the dataset annotations in the future.
Code availability
All anonymization steps were computed in Python 3.8.2 on a Windows 8.1 platform as described in the Methods section. We are not able to publicly share the actual code involved in the de-identification procedure, as patient information was processed. The de-identification procedure should be sufficiently reproducible based onto the presented information.
We attached a Jupyter notebook that is able to preview images including tags and labeled objects (“annotation_preview.ipynb”). It can be found in the “notebooks” folder and online at Figshare under https://doi.org/10.6084/m9.figshare.19330688.v143. The dataset is accompanied by a Jupyter notebook that is able to split files into different folders, based onto two columns of a CSV file (“copy_files_by_csv.ipynb”). It is intended to efficiently prepare datasets for image classification tasks with the included “dataset.csv” file. Image post-processing code is publicly provided as second Jupyter notebook with the dataset (“image_conversion.ipynb”), also located in the “notebooks” folder.
References
Hedstrom, E. M., Svensson, O., Bergstrom, U. & Michno, P. Epidemiology of fractures in children and adolescents. Acta Orthop 81, 148–153 (2010).
Randsborg, P. H. et al. Fractures in children: epidemiology and activity-specific fracture rates. The Journal of bone and joint surgery. American volume 95, e42 (2013).
Landin, L. A. Epidemiology of children’s fractures. J Pediatr Orthop B 6, 79–83 (1997).
Burki, T. K. Shortfall of consultant clinical radiologists in the UK. Lancet Oncol 19, e518 (2018).
Rimmer, A. Radiologist shortage leaves patient care at risk, warns royal college. BMJ 359, j4683 (2017).
Rosman, D. et al. Imaging in the Land of 1000 Hills: Rwanda Radiology Country Report. (2015).
Guly, H. R. Diagnostic errors in an accident and emergency department. Emerg Med J 18, 263–269 (2001).
Mounts, J., Clingenpeel, J., McGuire, E., Byers, E. & Kireeva, Y. Most frequently missed fractures in the emergency department. Clin Pediatr (Phila) 50, 183–186 (2011).
Er, E., Kara, P. H., Oyar, O. & Unluer, E. E. Overlooked extremity fractures in the emergency department. Ulus Travma Acil Cerrahi Derg 19, 25–28 (2013).
Juhl, M., Moller-Madsen, B. & Jensen, J. Missed injuries in an orthopaedic department. Injury 21, 110–112 (1990).
Fotiadou, A., Patel, A., Morgan, T. & Karantanas, A. H. Wrist injuries in young adults: the diagnostic impact of CT and MRI. Eur J Radiol 77, 235–239 (2011).
Welling, R. D. et al. MDCT and radiography of wrist fractures: radiographic sensitivity and fracture patterns. AJR. American journal of roentgenology 190, 10–16 (2008).
Neubauer, J. et al. Comparison of Diagnostic Accuracy of Radiation Dose-Equivalent Radiography, Multidetector Computed Tomography and Cone Beam Computed Tomography for Fractures of Adult Cadaveric Wrists. PLoS One 11, e0164859 (2016).
Adams, S. J., Henderson, R. D. E., Yi, X. & Babyn, P. Artificial Intelligence Solutions for Analysis of X-ray Images. Canadian Association of Radiologists journal = Journal l’Association canadienne des radiologistes, 846537120941671 (2020).
Tanzi, L. et al. Hierarchical fracture classification of proximal femur X-Ray images using a multistage Deep Learning approach. Eur J Radiol 133, 109373 (2020).
Chung, S. W. et al. Automated detection and classification of the proximal humerus fracture by using deep learning algorithm. Acta Orthop 89, 468–473 (2018).
Choi, J. W. et al. Using a Dual-Input Convolutional Neural Network for Automated Detection of Pediatric Supracondylar Fracture on Conventional Radiography. Investigative radiology 55, 101–110 (2020).
Gan, K. et al. Artificial intelligence detection of distal radius fractures: a comparison between the convolutional neural network and professional assessments. Acta Orthop 90, 394–400 (2019).
Kim, D. H. & MacKinnon, T. Artificial intelligence in fracture detection: transfer learning from deep convolutional neural networks. Clin Radiol 73, 439–445 (2018).
Lindsey, R. et al. Deep neural network improves fracture detection by clinicians. Proc Natl Acad Sci USA 115, 11591–11596 (2018).
Bluthgen, C. et al. Detection and localization of distal radius fractures: Deep learning system versus radiologists. Eur J Radiol 126, 108925 (2020).
Yahalomi, E., Chernofsky, M. & Werman, M. Detection of Distal Radius Fractures Trained by a Small Set of X-Ray Images and Faster R-CNN. 971–981 (Springer International Publishing, Cham, 2019).
Saba, L. et al. The present and future of deep learning in radiology. Eur J Radiol 114, 14–24 (2019).
Yamashita, R., Nishio, M., Do, R. K. G. & Togashi, K. Convolutional neural networks: an overview and application in radiology. Insights Imaging 9, 611–629 (2018).
Rajpurkar, P. et al. MURA Dataset: Towards Radiologist-Level Abnormality Detection in Musculoskeletal Radiographs. http://arxiv.org/abs/1712.06957 (2017).
Graham, R. N., Perriss, R. W. & Scarsbrook, A. F. DICOM demystified: a review of digital file formats and their use in radiological practice. Clin Radiol 60, 1133–1140 (2005).
Larobina, M. & Murino, L. Medical image file formats. Journal of digital imaging 27, 200–206 (2014).
DICOM Standards Committee. DICOM PS3.1 2020e - Introduction and Overview. http://dicom.nema.org/medical/dicom/current/output/chtml/part01/PS3.1.html (NEMA, 2020).
Mason, D.L. et al. pydicom: An open source DICOM library. https://github.com/pydicom/pydicom.
Aumasson, J.-P., Neves, S., Wilcox-O’Hearn, Z. & Winnerlein, C. BLAKE2: simpler, smaller, fast as MD5. in Proceedings of the 11th international conference on Applied Cryptography and Network Security 119–135, https://doi.org/10.1007/978-3-642-38980-1_8 (Springer-Verlag, Banff, AB, Canada, 2013).
National Institute of Standards and Technology (NIST). FIPS PUB 202: SHA-3 Standard: Permutation-Based Hash and Extendable-Output Functions. 37 (Gaithersburg, 2015).
Nagy, E., Janisch, M., Hrzic, F., Sorantin, E. & Tschauner, S. GRAZPEDWRI-DX. figshare https://doi.org/10.6084/m9.figshare.14825193 (2022).
Everingham, M., Van Gool, L., Williams, C. K. I., Winn, J. & Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. International Journal of Computer Vision 88, 303–338 (2010).
Jocher, G. et al. ultralytics/yolov5: v3.1 - Bug Fixes and Performance Improvements. zenodo https://doi.org/10.5281/zenodo.4154370 (2020).
Loesaus, J., Wobbe, I., Stahlberg, E., Barkhausen, J. & Goltz, J. P. Reliability of the pronator quadratus fat pad sign to predict the severity of distal radius fractures. World J Radiol 9, 359–364 (2017).
Moosikasuwan, J. B. The pronator quadratus sign. Radiology 244, 927–928 (2007).
Meinberg, E. G., Agel, J., Roberts, C. S., Karam, M. D. & Kellam, J. F. Fracture and Dislocation Classification Compendium—2018. Journal of Orthopaedic Trauma 32(1) S1–S10 https://doi.org/10.1097/BOT.0000000000001063.
Wei, C. J. et al. Systematic analysis of missed extremity fractures in emergency radiology. Acta Radiol 47, 710–717 (2006).
Memarsadeghi, M. et al. Occult scaphoid fractures: comparison of multidetector CT and MR imaging–initial experience. Radiology 240, 169–176 (2006).
Lin, T.-Y. et al. Microsoft COCO: Common Objects in Context. 740–755 (Springer International Publishing, Cham, 2014).
van der Walt, S. et al. scikit-image: image processing in Python. PeerJ 2, e453 (2014).
Stanford University Center for Artificial Intelligence in Medicine & Imaging. LERA- Lower Extremity RAdiographs. https://aimi.stanford.edu/lera-lower-extremity-radiographs (2020).
Nagy, E., Janisch, M., Hrzic, F., Sorantin, E. & Tschauner, S. GRAZPEDWRI-DX notebooks. figshare https://figshare.com/articles/software/GRAZPEDWRI-DX_notebooks/19330688 (2022).
Acknowledgements
We thank all colleagues, guest doctors and students that were involved in processing various amounts of the GRAZPEDWRI-DX dataset over the last years.
Author information
Authors and Affiliations
Contributions
S.T. generated the database and retrieved the images from PACS. E.N. drafted the paper. F.H. helped in de-identifying the images and establishing the database. M.J., E.N., and S.T. annotated the majority of images, and supervised image labeling by other annotators. M.J., E.N. and S.T. manually reviewed all images to ensure de-identification. E.S. supervised the project and provided feedback on the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nagy, E., Janisch, M., Hržić, F. et al. A pediatric wrist trauma X-ray dataset (GRAZPEDWRI-DX) for machine learning. Sci Data 9, 222 (2022). https://doi.org/10.1038/s41597-022-01328-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-022-01328-z
This article is cited by
-
Supervised representation learning based on various levels of pediatric radiographic views for transfer learning
Scientific Reports (2024)
-
Multi-Class Deep Learning Model for Detecting Pediatric Distal Forearm Fractures Based on the AO/OTA Classification
Journal of Imaging Informatics in Medicine (2024)
-
FracAtlas: A Dataset for Fracture Classification, Localization and Segmentation of Musculoskeletal Radiographs
Scientific Data (2023)
-
Fracture detection in pediatric wrist trauma X-ray images using YOLOv8 algorithm
Scientific Reports (2023)
