
Abstract
Percolation is a process that impairs network connectedness by deactivating links or nodes. This process features a phase transition that resembles paradigmatic critical transitions in epidemic spreading, biological networks, traffic and transportation systems. Some biological systems, such as networks of neural cells, actively respond to percolation-like damage, which enables these structures to maintain their function after degradation and aging. Here we study percolation in networks that actively respond to link damage by adopting a mechanism resembling synaptic scaling in neurons. We explain critical transitions in such active networks and show that these structures are more resilient to damage as they are able to maintain a stronger connectedness and ability to spread information. Moreover, we uncover the role of local rescaling strategies in biological networks and indicate a possibility of designing smart infrastructures with improved robustness to perturbations.
Similar content being viewed by others

Introduction
The resilience of complex networks to withstand failures and attacks is one of their most intriguing properties1. When edges have equal strengths, resilience can be studied with the mathematical framework of percolation2—a stochastic process akin to the permeation of a liquid through a porous membrane. This process removes edges uniformly at random with some given probability. The large-scale connectivity of the network is then studied by tracking the size of the largest connected component (LCC) as a function of this probability3,4. The size of LCC indicates what fraction of the whole network stays connected after damage, and in contexts such as transportation or communication—connected means functional. Studying percolation helps to understand the contribution of the network structure to its resilience, and both first- and second-order phase transitions in the size of LCC have been observed across a wealth of studies1,4,5,6,7,8. The most notable example refers to explaining the spreading of a disease driven by the susceptible–infected–recovered contact process. Percolation in a random network is identical to this process when the infectious time is constant9 and leads to a useful approximation otherwise10. Percolation has been also used to understand the early stages of formation of the brain by probing how resilient are interconnected neuronal cultures in vitro11,12.
When links feature different strengths (also called weights or capacities), both the structure and link weights contribute to network resilience, for example, as it happens with road and airline networks, the Internet, electricity grid, and financial networks. The role of such weights in network resilience can be mathematically studied with filtration13,14, a process that removes all edges with a weight less than a given threshold. This process can be thought of as a permeation of a liquid with insoluble particles through a porous membrane, wherein the particles may flow through a pore only after they have clogged it up, otherwise, they remain filtrated.
Optimizing the distribution of link weights to secure a more resilient network is an old problem: in epidemiology, it is known as targeted immunization15, but it also occurs in electrical engineering when designing efficient power grids, and urban planning when improving the traffic flow capacity of road networks. Apart from wide use in the top-down design, several biological complex systems were also observed to employ local self-regulation of link strengths with a positive effect on the global functioning of the whole network16,17. Both brain networks and food webs are believed to perform link strengths optimization by virtue of a self-regulatory mechanism that is triggered in response to damage.
In such systems, filtration-like processes are accompanied by an active response that mitigates the damage due to removed links. Neurons are hypothesized to control their activity using synaptic scaling18,19, a mechanism that allows neurons to adjust their synaptic strengths to conserve the overall neural activity despite external perturbations or damage19,20,21. In a similar fashion, food webs representing the dynamical system for inter-species mass/energy transporting have also been observed to feature a high degree of coherence that may be a consequence of self-regulation and adaptive rewiring22,23,24,25. Load redistribution and rewiring mechanisms are thought to have shaped the core-periphery structure of the world airline network26. At the same time, self-regulation-inspired principles were also proposed to be used in top-down intervention scenarios for preventing species extinction in ecosystems27.
Results
In the remainder, we present a mathematical theory for damage-response processes in complex networks that explains how maintaining local conservation of the total in- (or out-) weights of a node reflects on the global connectedness of the whole system. To this end, we consider a directed random network model with positive weights on edges. An instance of such a network is defined by a weighted adjacency matrix \({A}_{ij}\in {{\mathbb{R}}}^{+}\) if node i points to node j, otherwise Aij = 0.
We model the adaptive network degradation by several iterations of the filtration stage, followed by an update of the weights of the survived edges according to a homeostatic plasticity principle, that is conservation of the sum of all in-weights for each node. This principle is inspired by the conservation of the total pre-synaptic strength observed in neurons20. Using this theory, we show that a simple local self-regulatory mechanism actively adjusting link weights in a fashion similar to the synaptic scaling in neurons20, may significantly improve large-scale connectivity of the whole network and hence maintain network functioning, even if the damage has caused a loss of a large fraction of links. Note that the concept of homeostatic plasticity we adopt here is different from the one of homeostasis that usually appears in the literature of dynamical systems28,29, which instead is generally related to the properties of stable fixed points in systems of ODEs.
To consider a general setting, our directed network model is defined by an arbitrary degree-weight distribution, fk(x), the probability that a uniformly chosen directed edge has weight in the interval [x, x + dx] and terminates at the node of in-degree k. The joint distribution can be factorized, fk(x) = lkwk(x), where the excess-degree distribution lk, ∑k≥0lk = 1 is the probability that a randomly chosen edge terminates at a node of in-degree k, and wk(x) satisfying \(\int\nolimits_{0}^{\infty }{w}_{k}(x){{{{{{{\rm{d}}}}}}}}x=1\) is the probability density function for edges that terminate at a node of in-degree k. One step of the damage-response cycle is introduced as an operator \({{{{{{{\mathcal{A}}}}}}}}\) acting on the degree-weight distribution, \({f}_{k}^{1}(x)={{{{{{{\mathcal{A}}}}}}}}{f}_{k}^{0}(x),\) where \({f}_{k}^{0}\) is the distribution before the edge removal and \({f}_{k}^{1}\) is the distribution after the damage-response cycle. This operator can be further decoupled as a convolution product of the damage \({{{{{{{{\mathcal{D}}}}}}}}}_{k,y}\) and response \({{{{{{{{\mathcal{R}}}}}}}}}_{k,y}\) operators
Here, the contribution to the probability density of degree-k nodes comes from the nodes with higher degrees due to the fact that some edges are removed but none are added, and the surviving edges increase their weights as captured by the convolution operation (“*”) along the weight dimension x. See the “Methods” section for more details.
Our operator \({{{{{{{\mathcal{A}}}}}}}}\) provides a general framework for studying the phenomenon of adaptive degradation. Let us now consider a particular instance of degradation/response mechanism wherein the former is represented by filtration, removing all edges with the weight below a given threshold y, and the latter is given by the following redistribution rule. For a node of degree k, the weights of the in edges xi, i = 1, . . . , k are updated according to
where m is the total number of edges for which xi > y, and \({{\Delta }}={\sum }_{\{i,{x}_{i}\,{ < }\,y\}}{x}_{i}\) is the sum of all removed weights. A simple check shows that similarly to homeostatic response in neurons, ∑ixi is conserved. Methods section provides the explicit forms of \({{{{{{{{\mathcal{D}}}}}}}}}_{k,y}\) and \({{{{{{{{\mathcal{R}}}}}}}}}_{k,y}\) for this mechanism.
In the first panel of Fig. 1, we present a sketchy representation of the process described by rule (2), while the second panel illustrates multiple successive steps of the filtration process with and without homeostatic response on an example of a small synthetic network. One can see that the homeostatic response mechanism mitigates the degradation process by enabling the network to withstand larger filtration thresholds. In Fig. 2 we use master equation (1) to quantify the evolution of the degree-weight distribution caused by the multi-step damage/response process in a larger synthetic random network of N = 5 × 104 nodes, and normally distributed weights. Validation of these predictions with stochastic simulations shows that our equation is highly capable to predict complex patterns revealed by the simulations.

a Pictorial representation of the damage–response process for a given node i. Here, in the damaged state, one of the three initial in-edges is removed, hence its weight, w2, is equally redistributed among the surviving edges, in order to conserve the local in-strength of the initial state. b Several snapshots illustrating an example of multi-step degradation on a small network, governed by: filtration, where every edge is removed if its weight is below a given threshold (first row), and filtration with the homeostatic response that maintains the total weight of in-edges at a constant level (second row). The bars below the panels indicate the distribution of edge weights (black) and the value of the threshold red.

Evolution of the total weight distribution w(x) on four successive instances of filtration without response (upper panel), or with the homeostatic response (lower panel), on a large random regular graph of N = 5 × 104 nodes, degree z = 4 and normally distributed edge weights, at increasing values for the threshold y. The network has been generated according to the directed configuration model42, while the edge weights are distributed according to Gaussian distribution with mean μ = 0.5 and standard deviation σ = 0.1. Each plot shows the empirical weight distribution from stochastic simulations (blue histogram) compared with the prediction derived from our model (orange solid line). The vertical dashed red line in each plot represents the value of y.
From the structural point of view, the connectivity of the whole network is characterized by the largest component in which nodes are path-connected regardless of the direction of the links—the largest weakly connected component. We estimate the size of this component, SW, from the degree distributions for different increasing values of the threshold y, using the theory introduced by one of us30. In the multi-step setting, when the degradation occurs in a series of filtration-response steps, we observe that the disruption of SW is significantly postponed when compared to the case of no active response.
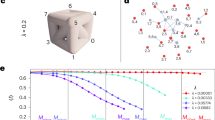
Figure 3 illustrates the percolation transition being significantly delayed as a result of the homeostatic response in a random graph and an empirical brain network31,32. The values obtained from direct numerical simulations of SW (colored markers) are well captured by the estimates (black× and +markers) obtained by the directed configuration model30 supplied with the degree-distributions derived from the master equation (1).

Evolution of the weak giant component’s size, SW, as a function of the threshold y, for a a regular random graph of N = 2 × 104 nodes and degree z = 4 with Gaussian distributed weights (the same distribution of Fig. 2), and b a brain network of N = 983 nodes representing a volume of the mouse neocortex31, 32 with uniformly distributed weights in the interval [0,1]. Colored markers represent the outcome of Monte Carlo simulations, obtained by averaging over 100 realizations of the weight distribution for the regular graph, and 1000 realizations for the real dataset. In both cases, we considered 20 successive steps of filtration without response (red circles) and with the homeostatic response (blue squares). Black markers represent the corresponding estimates from the model for each value of y, while gray dashed and dash-dotted lines represent linear interpolations between theoretical values, which serve only as visual guidelines.
Successive steps of the damage–response process may only occur in a system that quickly responds to an external perturbation. In some systems, synaptic scaling is reported to have a typical time of hours/days after external damage20,33. Therefore, we also analyze a single step of the process, mimicking a relatively slow response. As explained in the “Methods” section, in the single-step case, our model can be solved analytically provided the initial network does not have weight-degree correlations. Then even a single step introduces nontrivial correlations between weights and degrees (see “Methods” section for details), by which we lose the analytical tractability. Therefore letting wk(x, y = 0) = w(x, y = 0) be the initial weight distribution, the average weight after a single step of the damage–response process at threshold y, \(\bar{w}(y)=\int\nolimits_{0}^{\infty }xw(x,y)dx\), reads
where \(F(y)=\int\nolimits_{0}^{y}w(x)dx\) is the initial cumulative weight distribution
and G(z) = ∑k≥0lkzk—the generating function of lk.
The second term of Eq. (3) represents the contribution from the homeostatic response. As a matter of fact, one may verify that β1(y) coincides with the average weight in the case of no response (see the “Methods” section). On the other hand, the average degree after the damage is simply given by
where \(\bar{k}(0)\) stands for the initial average degree.
Figure 4 shows a very good agreement between our analytical predictions and stochastic simulations for the values of the average weight \(\bar{w}(y)\) and the average degree \(\bar{k}(y)\), in both synthetic and real networks.

Colored markers represent the outcome of a single stochastic simulation. Solid and dashed lines represent the analytical results for average weight and degree (derived in the Methods section). Red dots and continuous lines represent the average degree (left scale), while blue triangles and dashed lines represent the average weight (right scale). a Poisson network of N = 25 × 103 nodes and uniform weights. b Random regular graph with N = 25 × 103 nodes and normally distributed weights (same distribution of Fig. 2). c Scale-free network of N = 25 × 103 nodes with power-law exponent γ = 2.5 and uniform weights. d Empirical network with uniform distributed weights (same network as in Fig. 3b).
Note that, by construction, our framework naturally takes into account the correlation between weights and degrees. In the “Methods” section we prove that, for a single instance of the damage–response process, the sign of this correlation is strongly affected by the underlying network topology, in particular, it is positive for scale-free networks, e.g., edges pointing to higher degree nodes have higher weights, while is negative for both random regular and Erdös–Rényi networks, e.g., edges pointing to higher degree nodes have lower weights.
From the results of Fig. 4, it is evident that \(\bar{k}(y)\) is a decreasing function in y, while \(\bar{w}\) is an increasing function in y. One can verify from equations (3) and (6) that this is true in general. In the Methods section, we show that the product of the two, that is \(\bar{w}\bar{k}\), coincides with the network average strength \(\bar{S}\). This quantity tends to be quasi-conserved for small values of y in the absence of low-degree nodes (see Methods section), which is easily understood when we look back at the local rule (2): for each node i the local strength is conserved only if at least one edge survives the filtration process, otherwise, the lost weight is not redistributed.
We can use the analytical estimate for \(\bar{S}\) in order to approximate the leading eigenvalue of the network λmax: in the case of weighted directed networks, λmax is approximated by \(\overline{{S}_{{{{{\rm{in}}}}}}{S}_{{{{{\rm{out}}}}}}}/\overline{S}\)34,35, which approaches the average strength as we neglect in/out strength correlations.
Hence, by combining Eqs. (3) and (6) we can assess the behavior of λmax as well as other spectral properties. To this end we consider, as an example, the trace of the communicability matrix, i.e., the Estrada index (EE)36, motivated by the recent applications in the fields of both brain networks37,38 and traffic flows in cities39. Note that in this case, since both λmax and EE depend on the weights, the effect of the damage/response process is observable also in the single-step case, while when we considered SW, because the giant component is determined by the degree distribution only, the effect of the homeostatic response can only be seen in the multi-step case, for which we are sure that weight-degree correlations have formed.
Figure 5 shows that, similarly to the case of SW, the homeostatic response has a clear effect of sustaining high values of both λmax and EE, compared to the case where no response is present. Moreover, in the case of a random regular network with uniformly distributed weights, the estimation of λmax by means of \(\bar{S}=\bar{w}\bar{k}\) is quite accurate, both in the single-step case (panel a) and in the successive-steps case (panel b). Hence, we approximate the value of \({{{{{\rm{EE}}}}}}={\sum }_{n}{e}^{{\lambda }_{n}}\)36, by keeping the contribution of the largest eigenvalue plus the 0th order of the remaining part of the spectrum. Therefore, for this particular case we have \({{{{{\rm{EE}}}}}} \sim N-1+{e}^{{\lambda }_{{{{{\rm{max}}}}}}} \sim N-1+{e}^{\bar{w}\bar{k}}\). From Fig. 5, we see that this approximation is less accurate, but does not fail to capture the general behavior emerging from stochastic simulations.

Continuous and dashed black lines represent the values from our model in the case of homeostatic response and no response respectively, while colored markers and colored shaded areas represent mean values and interquartile ranges derived from stochastic simulations. We averaged the damage-response process over 200 realizations of a random regular network of N = 103 nodes and average degree z = 10 with uniform weights. a, c Single instances of the damage–response process. In this case \(\bar{w}\bar{k}\) is simply given by combining Eqs. (3) and (6). b, d Successive instances of the damage–response process. Here, both \(\bar{w}\) and \(\bar{k}\) are computed at each step from the master equation (1). In every panel, β1 is computed from Eq. (4).
Discussion
To summarize, percolation-like processes that conceptualize random damage in networks have been since long viewed as prototypical models for complex systems resilience. However, systems that actively maintain their homeostatic response tend to have the means to respond and actively adapt to such damage. We have presented a theory that naturally extends the classical percolation framework to a more complex one that incorporates the principle of homeostatic plasticity. Being a natural extension of simple percolation, our framework is still a theoretical abstraction but is not size-limited. Therefore, it is able to project the effects of local homeostatic mechanisms, similar to the ones observed in real biological systems at small sizes16,40, at arbitrarily large scales, thus overcoming the practical limitations of laboratory experiments. By means of our model, it is possible to show that a simple local self-regulatory mechanism may significantly improve the large-scale functionality of the whole network compared to the case in which such a mechanism is absent. Our results reproduce the evolution of the joint weight-degree distribution of the network, which allows predicting the behavior of several global indicators of network structure and dynamics, such as the size of the largest connected component, the largest eigenvalue, and the Estrada index.
Overall our results provide a first mathematical framework for studying the link between local homeostatic plasticity rule in complex networks and its effect on the global functionality, and may also shed light on how the self-regulatory mechanisms observed in biological systems might be transferred to improve the resilience of human-designed infrastructures, for example, communication or transport networks, wherein it is reasonable to assume that homeostatic response might be adopted to mitigate external damage.
Methods
Notation and master equation
We consider a general model for homeostatic plasticity in a random directed network wherein all edges have a weight x > 0. According to this process, the network updates the edges' weights in a response to filtration, which is a deterministic and simultaneous removal of all edges with a weight strictly below a certain threshold y. Such a response can be adopted, for example, to mitigate further damage due to filtration in the future20,41. We consider networks wherein each node has at most one in-edge and possibly many out-edges and adopt the following notation to analyze the evolution of the network structure:
-
pk is the in-degree distribution. Related to this quantity is \(\bar{k}:= {\sum }_{k\ge 0}k{p}_{k}\)—the average degree, and \({l}_{k}:= k{p}_{k}/\bar{k}\)—the excess degree distribution, which denotes the probability of uniformly at random picking an edge sitting on a node of in-degree k.
-
wk(x) is the probability density function such that \({\mathbb{P}}(w > x| deg=k)=\int\nolimits_{x}^{\infty }{w}_{k}(\tau ){{{{{{{\rm{d}}}}}}}}\tau\) is the probability of picking an in-edge with a weight greater than x, given that it points to a node with in-degree k. Note that plasticity may result in weight-degree correlation (see the last section), therefore \({\mathbb{P}}(w \, > \, x| deg=k)\,\ne\, {\mathbb{P}}(w \, > \, x)\).
-
fk(x) ≔ lkwk(x) is the joint probability density function, corresponding to the event of picking an edge with weight w ∈ [x, x + dx] pointing to a node of in-degree k. Let us denote the marginal distributions of fk(x) as
$${l}_{k}:= \int\nolimits_{0}^{\infty }{f}_{k}(x){{{{{{{\rm{d}}}}}}}}x,$$$$w(x):= \mathop{\sum}\limits_{k\ge 0}{f}_{k}(x).$$
Since the response mechanism involves the weights of in-edges only, we refer to the in-degree as k. Response of degree-weight density function \({f}_{k}^{0}(x)\) to filtration with threshold y > 0 is given by
where
In Eq. (7), the contribution to the kth-degree nodes after filtration comes from nodes with degree n ≥ k. For these nodes, Damage operator \({{{{{{{{\mathcal{D}}}}}}}}}_{k,y}\) conceptualizes the effect of filtration on the node degrees and edge weights, whereas the Response operator \({{{{{{{{\mathcal{R}}}}}}}}}_{k,y}\) represents the response to filtration by increasing weights of surviving edges. The convolution operation \(*\) is defined by \((f* g)(x):= \int\nolimits_{-\infty }^{\infty }f(\tau )g(x-\tau ){{{{{{{\rm{d}}}}}}}}\tau\).
The Damage operator
The Damage on the network is represented by a filtration process in which all the edges with weight below a fixed threshold y are removed. In order to get the explicit form of \({{{{{{{{\mathcal{D}}}}}}}}}_{k,y}{f}_{n}(x)\) we compute the damaged excess degree distribution lk(y) and the damaged weight distributions \({w}_{k}^{D}(x,y)\). The latter is simply given by the original weight distribution wk(x, 0) cut and renormalized
where Fk(y) indicates the cumulative distribution function of wk(x, 0), defined as
On the other hand by definition \({l}_{k}(y)=k{p}_{k}(y)/\bar{k}(y)\), hence we just need to compute the damaged degree distribution. For every node of degree n, each of the n in-edges may be removed with probability Fn(y), therefore we have
where B(k, n, 1 − Fn(y)) denotes a binomial distribution with parameters (k, n, 1 − Fn(y)).
The average degree after damage is then given by
were we defined \({\langle {f}_{k}\rangle }_{y}:= {\sum }_{k\geq0}{f}_{k}{l}_{k}(y)\).
With this notation one can rewrite Eq. (10) in terms of the excess degree distribution lk, which, combined with Eq. (8), finally yields the explicit form of the Damage operator
The Response operator
Here, we present the explicit form for the response operator \({{{{{{{{\mathcal{R}}}}}}}}}_{k,y}\) introduced in Eq. (7) for our particular case in which the response is locally specified by the rule (2). In terms of a probability distribution, similarly to Eq. (8) we first compute the distributions of the deleted weights \({w}_{k}^{c}(x,y)\) which is given by
From Eq. (13) we get the explicit form of \({{{{{{{{\mathcal{R}}}}}}}}}_{k}\) by considering the distribution associated with the sum of n − k deleted edges scaled by a factor k
Overall we can now write the explicit form of the master equation (7) for this process
By repetitively applying Eq. (15) at increasing values for y we get the evolution of fk(x) for a multi-step process. The plots presented in Figs. 2 and 3 of the Results section are derived by computing the marginals of fk(x, y) at each step. In particular, the in-degree distribution is derived from \({l}_{k}=\int\nolimits_{0}^{\infty }{f}_{k}(x){{{{{{{\rm{d}}}}}}}}x\), combined with Eq. (11) and the definition \({p}_{k}=\bar{k}{l}_{k}/k\). On the other hand, the weight distribution is given by w(x, y) = ∑kfk(x, y). Finally, the out-degree distribution is simply given by directly applying Eq. (10) to the initial \({p}_{k}^{{{{{\rm{out}}}}}}\) at any value for y, since the response mechanism involves weights of in-edges only, hence no additional correlation between out-degrees and edge weights is introduced in the process. With both in and out-degree distributions, we then estimate the size of the weakly largest connected component, SW, for a directed configuration model30, as threshold y is increased.
Single-step from an initial state with no weight-degree correlation
Here, we show that if the initial configuration is given by a network with no weight-degree correlation, the outcome of a single damage-response step is analytically tractable.
Let wk(x, 0) = w(x, 0), so that the initial weight-degree distribution is given by fk(x, 0) = lk(0)w(x, 0) and the only cumulative weight distribution is given by \(F(y)=\int\nolimits_{0}^{y}w(x){{{{{{{\rm{d}}}}}}}}x\).
Under these assumptions, Eq. (15) can be rewritten as
where we highlighted in the square brackets the damaged weight distribution and the response operator. Let the convolution of the two be Wk,y(x). Its Laplace transform, defined as \({{{{{{{\mathcal{L}}}}}}}}(g(x))=\int\nolimits_{0}^{\infty }g(x){e}^{-sx}{{{{{{{\rm{d}}}}}}}}x\), reads
From the properties of the Laplace transform, it is then straightforward to obtain
where we defined
After having introduced the two functions above, we can conveniently write \(\bar{w}(y)\) as
where \(G(z)={\langle {z}^{k}\rangle }_{0}={\sum }_{k}{l}_{k}(0){z}^{k}\) is the generating function of lk(0).
The results were obtained by testing the predictions of Eqs. (19) and (11) on several networks (both synthetic and real) are shown in Fig. 4 of the main article.
Average strength quasi-conservation
From Eq. (2) it is easily verified that the local strength is conserved if at least one edge survives. Here we show that from Eq. (19), one can verify that under certain assumptions the average strength of the whole network \(\bar{S}\) is quasi-conserved. We start by showing that \(\bar{S}=\bar{w}\bar{k}\). By definition, the in/out strength of a node Si is defined by the sum of all the in/out weights. The strength distribution P(S = x) (either in or out) can therefore be written as
Note that we allow the presence of weight-degree correlation for the most general case. However, we do not allow the correlation between weights belonging to the same neighborhood.
The average strength, \(\bar{S}\), therefore reads
Let us now consider Eq. (19). We note that since F(y) ∈ [0, 1], the contribution given by G(F(y)) can be neglected if low degree nodes are not present and F(y) is small enough. Under these assumptions, Fk(y) ≪ 1, i.e., the probability that for a node of degree k there are no surviving edges after damage, is very small. Therefore Eq. (19) can be approximated by
where we used Eq. (11) with Fn(y) = F(y).
The above equation then implies
meaning that \(\bar{S}\) is quasi-conserved by the response mechanism.
The emergence of weight-degree correlation
In this last section, we show that a single instance of the damage response process generates either positive or negative weight-degree correlations. Since the sign of the correlation coefficient is determined by the one of covariance, we can focus ourselves on the covariance only. By definition \(\,{{\mbox{cov}}}\,(k,w)={\mathbb{E}}[kw]-{\mathbb{E}}[k]{\mathbb{E}}[w]\), which in our notation reads \({\langle k{\bar{w}}_{k}\rangle }_{y}-{\langle k\rangle }_{y}\bar{w}(y)\). Note that in our notation 〈k〉 is not the average degree, but it’s the first moment of the excess-degree distribution. By using again Eq. (17), one can obtain
which combined with the previous results yields
Note that β2(y) = 0 ⇒ cov(w, k; y) = 0, meaning that in the case of no response no additional weight-degree correlation is introduced, as expected.
From the last equation, we derive the condition
One can verify the condition above is never satisfied for either Erdös–Rényi or Random Regular networks (for the case of Random Regular networks although the strict inequality is never satisfied, the equality holds for extreme case of constant degree z = 1), while for Scale-Free networks the opposite result holds.
In Fig. 6, we show the comparison between the analytic theory and stochastic simulations on a random regular network and a scale-free one, both with uniform weight distribution.

The initial configurations are given by: a a N = 25 × 103 nodes random regular graph with uniform weight distribution and b a N = 25 × 103 nodes scale-free network with exponent γ = 2.5, with uniform weight distribution (right panel). In both plots red markers represent the results from a single stochastic simulation, while continuous black lines show the analytical values from the theory. As we can see in the regular graph case the covariance is always negative, while the opposite happens in the scale-free network case.
Data availability
The authors declare that all data supporting the findings of this study are available within the article.
Code availability
The code for reproducing the main findings of the article is available at the GitHub repository: https://github.com/grapisar/PercHomeostatic.
References
D’Souza, R. M., Gómez-Gardeñes, J., Nagler, J. & Arenas, A. Explosive phenomena in complex networks. Adv. Phys. 68, 123–223 (2019).
Bollobás, B. & Riordan, Oliver. Percolation. (Cambridge University Press, 2006).
Callaway, D. S., Newman, M. E. J., Strogatz, S. H. & Watts, D. J. Network robustness and fragility: percolation on random graphs. Phys. Rev. Lett. 85, 5468–5471 (2000).
Dorogovtsev, S. N., Goltsev, A. V. & Mendes, J. F. F. Critical phenomena in complex networks. Rev. Mod. Phys. 80, 1275–1335 (2008).
Boettcher, S., Singh, V. & Ziff, R. M. Ordinary percolation with discontinuous transitions. Nat. Commun. 3, 1–5 (2012).
Karrer, B., Newman, M. E. J. & Zdeborová, L. Percolation on sparse networks. Phys. Rev. Lett. 113, 208702 (2014).
Hu, Y., Ksherim, B., Cohen, R. & Havlin, S. Percolation in interdependent and interconnected networks: abrupt change from second- to first-order transitions. Phys. Rev. E 84, 066116 (2011).
Rapisardi, G., Arenas, A., Caldarelli, G. & Cimini, G. Fragility and anomalous susceptibility of weakly interacting networks. Phys. Rev. E 99, 042302 (2019).
Durrett, R. Random Graph Dynamics, volume 200. (Cambridge University Press, Cambridge, 2007).
Newman, M. E. J. Spread of epidemic disease on networks. Phys. Rev. E 66, 016128 (2002).
Breskin, I., Soriano, J., Moses, E. & Tlusty, T. Percolation in living neural networks. Phys. Rev. Lett. 97, 188102 (2006).
Soriano, J., Martínez, M. R., Tlusty, T. & Moses, E. Development of input connections in neural cultures. Proc. Natl Acad. Sci USA. 105, 13758–13763 (2008).
Allesina, S., Bodini, A. & Bondavalli, C. Secondary extinctions in ecological networks: bottlenecks unveiled. Ecol. Model. 194, 150–161 (2006). Special Issue on the Fourth European Conference on Ecological Modelling.
van den Heuvel, M. P. et al. Proportional thresholding in resting-state fMRI functional connectivity networks and consequences for patient-control connectome studies: Issues and recommendations. NeuroImage 152, 437–449 (2017).
Cohen, R., Havlin, S. & Ben-Avraham, D. Efficient immunization strategies for computer networks and populations. Phys. Rev. Lett. 91, 247901 (2003).
Teller, S. et al. Spontaneous functional recovery after focal damage in neuronal cultures. eNeuro 7, ENEURO.0254–19.2019 (2020).
Estévez-Priego, E., Teller, S., Granell, C., Arenas, A. & Soriano, J. Functional strengthening through synaptic scaling upon connectivity disruption in neuronal cultures. Netw. Neurosci. 4, 1160–1180 (2020).
de Vivo, L. et al. Ultrastructural evidence for synaptic scaling across the wake/sleep cycle. Science 355, 507–510 (2017).
Siddoway, B., Hou, H. & Xia, H. Molecular mechanisms of homeostatic synaptic downscaling. Neuropharmacology 78, 38–44 (2014). Homeostatic Synaptic Plasticity.
Turrigiano, G. G. The self-tuning neuron: synaptic scaling of excitatory synapses. Cell 135, 422–435 (2008).
Murphy, T. H. & Corbett, D. Plasticity during stroke recovery: from synapse to behaviour. Nat. Rev. Neurosci. 10, 861–872 (2009).
Johnson, S., Domínguez-García, V., Donetti, L. & Muñoz, M. A. Trophic coherence determines food-web stability. Proc. Natl Acad. Sci. USA 111, 17923–17928 (2014).
Neutel, A.-M. et al. Reconciling complexity with stability in naturally assembling food webs. Nature 449, 599–602 (2007).
Gilljam, D., Curtsdotter, A. & Ebenman, B. O. Adaptive rewiring aggravates the effects of species loss in ecosystems. Nat. Commun. 6, 1–10 (2015).
Staniczenko, P. P. A., Lewis, O. T., Jones, N. S. & Reed-Tsochas, F. Structural dynamics and robustness of food webs. Ecol. Lett. 13, 891–899 (2010).
Verma, T., Russmann, F., Araújo, N. A. M., Nagler, J. & Herrmann, H. J. Emergence of core–peripheries in networks. Nat. Commun. 7, 1–7 (2016).
Sahasrabudhe, S. & Motter, A. E. Rescuing ecosystems from extinction cascades through compensatory perturbations. Nat. Commun. 2, 1–8 (2011).
Golubitsky, M. & Stewart, I. Homeostasis, singularities, and networks. J. Math. Biol. 74, 387–407 (2017).
Golubitsky, M. & Stewart, I. Homeostasis with multiple inputs. SIAM J. Appl. Dyn. Syst. 17, 1816–1832 (2018).
Kryven, I. Finite connected components in infinite directed and multiplex networks with arbitrary degree distributions. Phys. Rev. E 96, 052304 (2017).
Kasthuri, N. et al. Saturated reconstruction of a volume of neocortex. Cell 162, 648–661 (2015).
Rossi, R.A. & Ahmed, N.K. The network data repository with interactive graph analytics and visualization. in AAAI, 2015.
Ibata, K., Sun, Q. & Turrigiano, G. G. Neuron 57, 819–826 (2008). Funding Information: This work was supported by NIH grant NS 36853 and NSF grant IBN 023519.
Bianconi, G., Gulbahce, N. & Motter, A. E. Local structure of directed networks. Phys. Rev. Lett. 100, 118701 (2008).
Restrepo, J. G., Ott, E. & Hunt, B. R. Approximating the largest eigenvalue of network adjacency matrices. Phys. Rev. E 76, 056119 (2007).
Estrada, E., Hatano, N. & Benzi, M. The physics of communicability in complex networks. Phys. Rep. 514, 89–119 (2012). The Physics of Communicability in Complex Networks.
Crofts, J. J. & Higham, D. J. A weighted communicability measure applied to complex brain networks. J. R. Soc. Interface 6, 411–414 (2009). 19141429[pmid].
Andreotti, J. et al. Validation of network communicability metrics for the analysis of brain structural networks. PLoS ONE 9, 1–26 (2015).
Akbarzadeh, M. & Estrada, E. Communicability geometry captures traffic flows in cities. Nat. Hum. Behav. 2, 645–652 (2018).
Keck, T. et al. Synaptic scaling and homeostatic plasticity in the mouse visual cortex in vivo. Neuron 80, 327–334 (2013).
Teichert, M., Liebmann, L., Hübner, C. A. & Bolz, J. Homeostatic plasticity and synaptic scaling in the adult mouse auditory cortex. Sci. Rep. 7, 17423 (2017).
Newman, M. E. J., Strogatz, S. H. & Watts, D. J. Random graphs with arbitrary degree distributions and their applications. Phys. Rev. E 64, 026118 (2001).
Acknowledgements
G.R. acknowledges the financial support of the Barcelona Supercomputing Center, A.A. acknowledges support by Ministerio de Economía y Competitividad (Grants No. PGC2018-094754-B-C21), Generalitat de Catalunya (Grant No. 2017SGR-896), Universitat Rovira i Virgili (Grant no. 2019PFR-URV-B2-41), ICREA Academia, and the James S. McDonnell Foundation (Grant no. 220020325). I.K. acknowledges the kind hospitality of the Alephsys lab at Universitat Rovira i Virgili.
Author information
Authors and Affiliations
Contributions
G.R. and I.K. developed the analytical theory and performed numerical simulations, G.R., I.K., and A.A. designed the project, interpreted results, and wrote the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review information
Nature Communications thanks the anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Rapisardi, G., Kryven, I. & Arenas, A. Percolation in networks with local homeostatic plasticity. Nat Commun 13, 122 (2022). https://doi.org/10.1038/s41467-021-27736-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-021-27736-0
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
