Review: Document parsing in AWS, Azure, and Google Cloud
Amazon Textract, Azure Form Recognizer, and Google Document AI can parse your unstructured documents and produce structured information for all kinds of digital transformation use cases.






Contributor, InfoWorld |
-
Amazon Textract
-
Microsoft Azure Form Recognizer
-
Google Cloud Document AI
Records have been written for thousands of years, in many scripts and on many media. Clay tablets, stone tablets, wax tablets, papyrus, parchment, and paper all preceded digital media. In our hurry to move from paper to digital media, the most common shortcut has been to scan paper into PDF documents, which have the virtue of being digital and portable, but the drawback of being essentially unstructured.
What companies need as they streamline their operations is structured data, but getting from unstructured to structured documents has been time-consuming. There have been many products and services offered for OCR (optical character recognition) and text mining, without there being an overall dominant player in the field. To understand the size of the problem, consider that 80% to 90% of data is currently unstructured, and the volume of unstructured data is growing from tens of zettabytes to hundreds of zettabytes. (One zettabyte is one billion terabytes.)
The usual approach to parsing a PDF document involves segmenting each page, applying OCR (often accomplished using convolutional neural networks), identifying the layout, extracting the text of interest, and converting digits to numeric values. Some services can take the next steps as well, extracting entities and inferring sentiment from selected text fields, such as articles, comments, and reviews.
In this article we’ll discuss the document parsing and splitting services available from the big three public cloud providers: AWS, Microsoft Azure, and Google Cloud. The use cases these services cover include extracting text and tagged values from lending and procurement documents, contracts, driver’s licenses, and passports.
AWS document parsers
Amazon Textract implements text extraction from JPEG, PNG, TIFF, and PDF documents in English, French, German, Italian, Portuguese, and Spanish. Amazon Comprehend performs language processing. Amazon Augmented AI implements human review of machine learning. The Amazon Document Understanding Solution uses the other services mentioned to implement an end-to-end pipeline.
 IDG
IDG
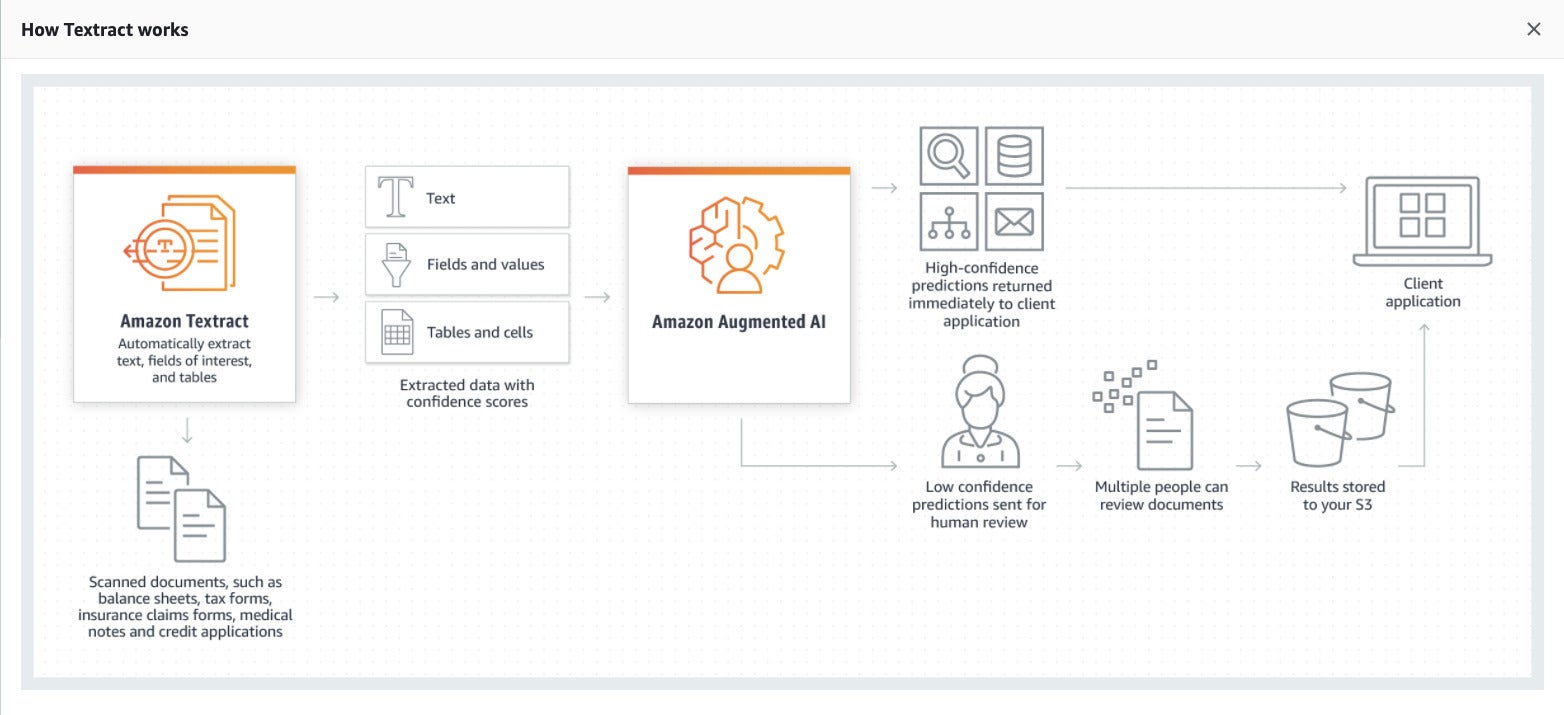
Amazon Textract extracts text, fields, values, tables, and cells from a document along with confidence scores. Values with low confidence can go for human review via Amazon Augmented AI.
Amazon Textract
Amazon Textract automatically extracts printed text, handwriting, and data from any document. It exposes three APIs: the Text Detection API, which uses OCR technology to extract text and handwriting from a provided document; the Document Analysis API, which has two functions, forms and tables; and the Analyze Expense API, which extracts data from invoices and receipts. Amazon Textract has pay-as-you-go pricing and supports the AWS Free Tier for new accounts.
Benefits of Amazon Textract include quick, accurate data extraction; document processing as cheaply as $1.50 per 1,000 pages; no code or templates to maintain (since Textract’s ML models are pre-trained); easy implementation of human reviews (with Amazon Augmented AI); and scalable document analysis. Features include key-value pair extraction; table extraction; handwriting recognition; invoice and receipt processing; bounding box extraction; and confidence scores with adjustable thresholds for human review.
Hard limits include restrictions on file types, file sizes, page limits, and text alignment. PDF files are only supported by asynchronous operations; synchronous and asynchronous operations support JPEG, PNG, and TIFF files. Size limits are much higher for asynchronous operations (500MB and 3,000 pages for PDF and TIFF files) than for synchronous operations (10MB, 1 page). Textract does not support vertical text alignment within the document, but it does support all in-plane document rotations.
Use cases for Textract include search index creation for document libraries; intelligent text extraction for subsequent natural language processing; extraction of text from heterogenous documents for research and due diligence; and extraction of structured text from forms to speed workflows (intelligent automation).
 IDG
IDG
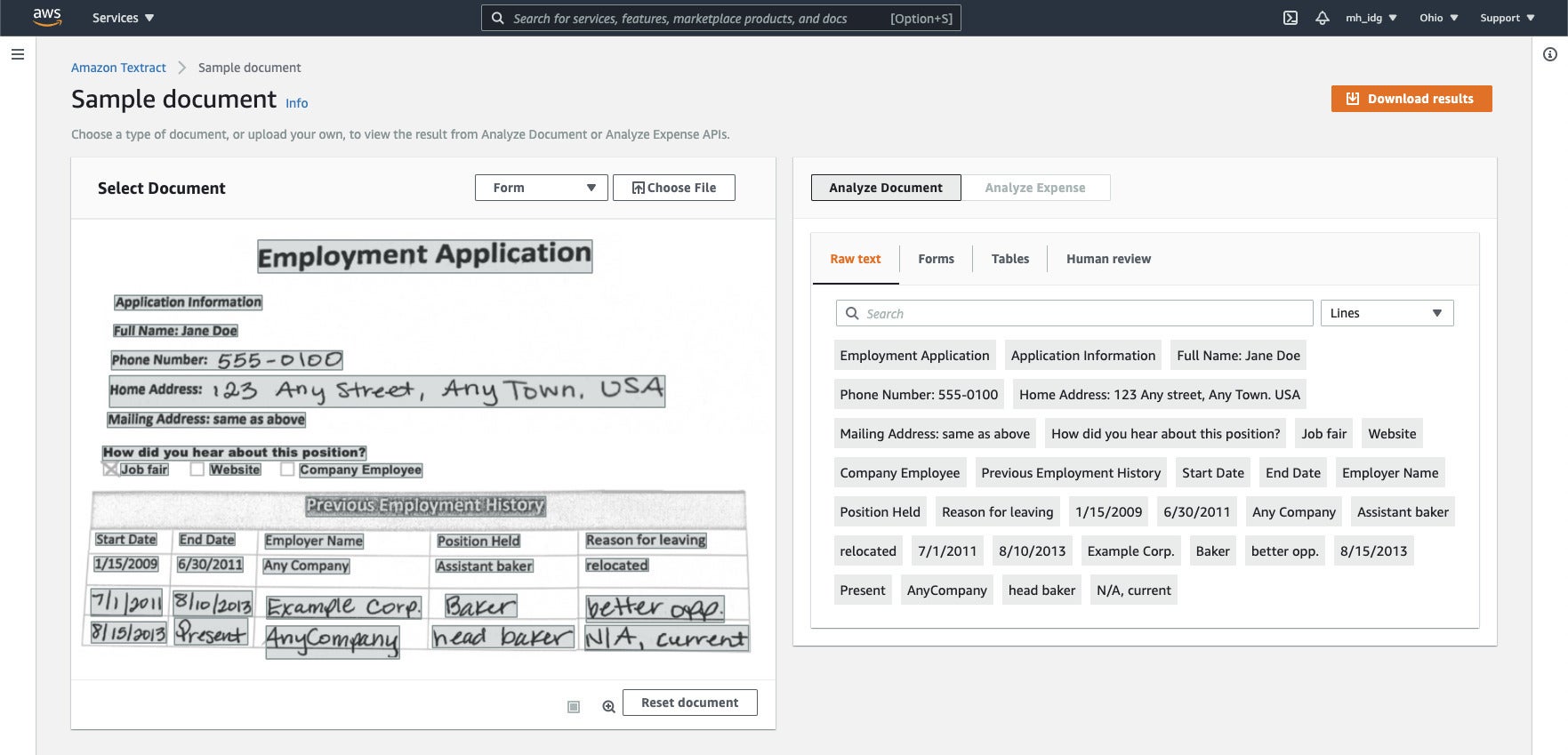
Amazon Textract form processing. The output chosen is raw text; the service can also extract forms (the top part of this document) and tables (the bottom part). Note the mix of printed and handwritten text in the original scanned document.
 IDG
IDG
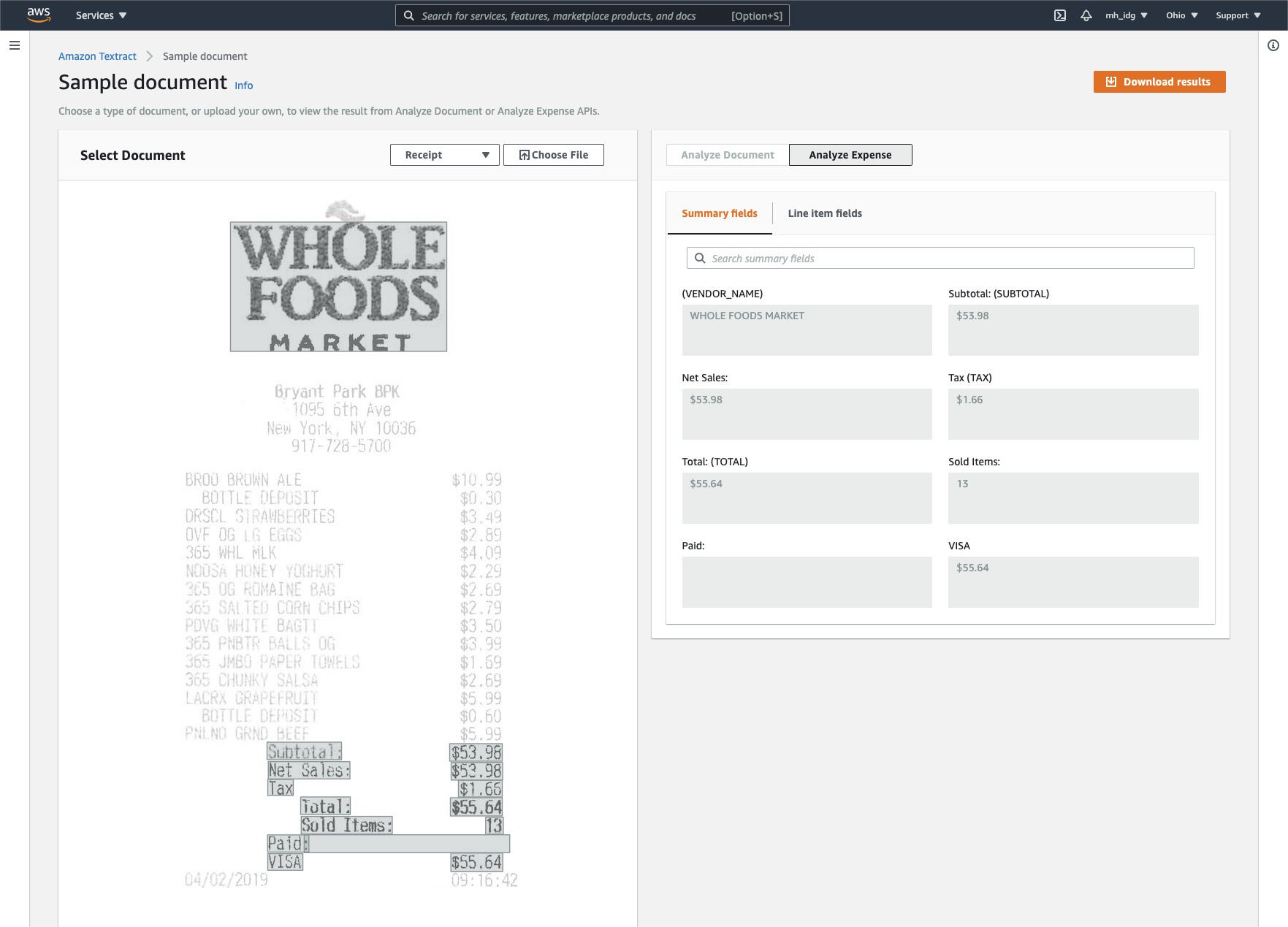
Amazon Textract expense analysis for a scanned Whole Foods receipt. Summary fields are displayed; the service can also extract line items.
Amazon Comprehend
Amazon Comprehend is a natural language processing (NLP) service that uses machine learning to uncover valuable insights and connections in text. Comprehend provides keyphrase extraction, sentiment analysis, entity recognition, topic modeling, and language detection APIs, among others.
It’s common to send Textract’s output to Comprehend for analysis. Comprehend requires text documents in UTF-8 character encoding.
Amazon Augmented AI
Amazon Augmented AI (aka Amazon A2I) easily implements human review of machine learning predictions. Essentially, Augmented AI takes the input document and the extracted text and generates an interface for the human reviewer to use to correct the output.
Augmented AI can decide which forms need review on the basis of a confidence level or a percentage for random sampling. You can also write an AWS Lambda function to direct the workflow.
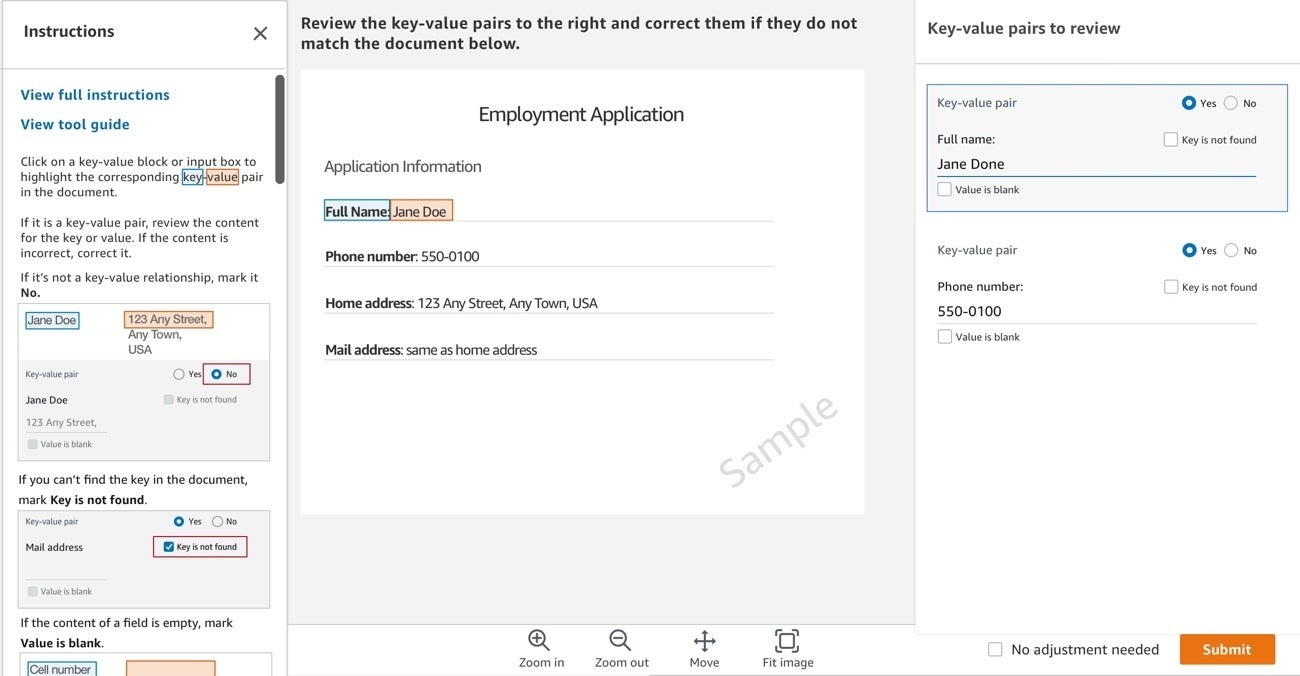 IDG
IDG
The image shows the reviewer interface for form extraction, which enables you to extract key-value pairs from document images or online forms. The interface allows you to specify clear instructions to help reviewers complete their tasks. In this image “Jane Doe” was extracted as “Jane Done” and needs correction.
Amazon Document Understanding Solution
Amazon Document Understanding Solution is a retrainable end-to-end document analysis solution with Amazon Textract, Amazon Comprehend, and Amazon Augmented AI. You can deploy this solution as a website for enterprise search, document digitization, discovery, and extraction and redaction of select information.
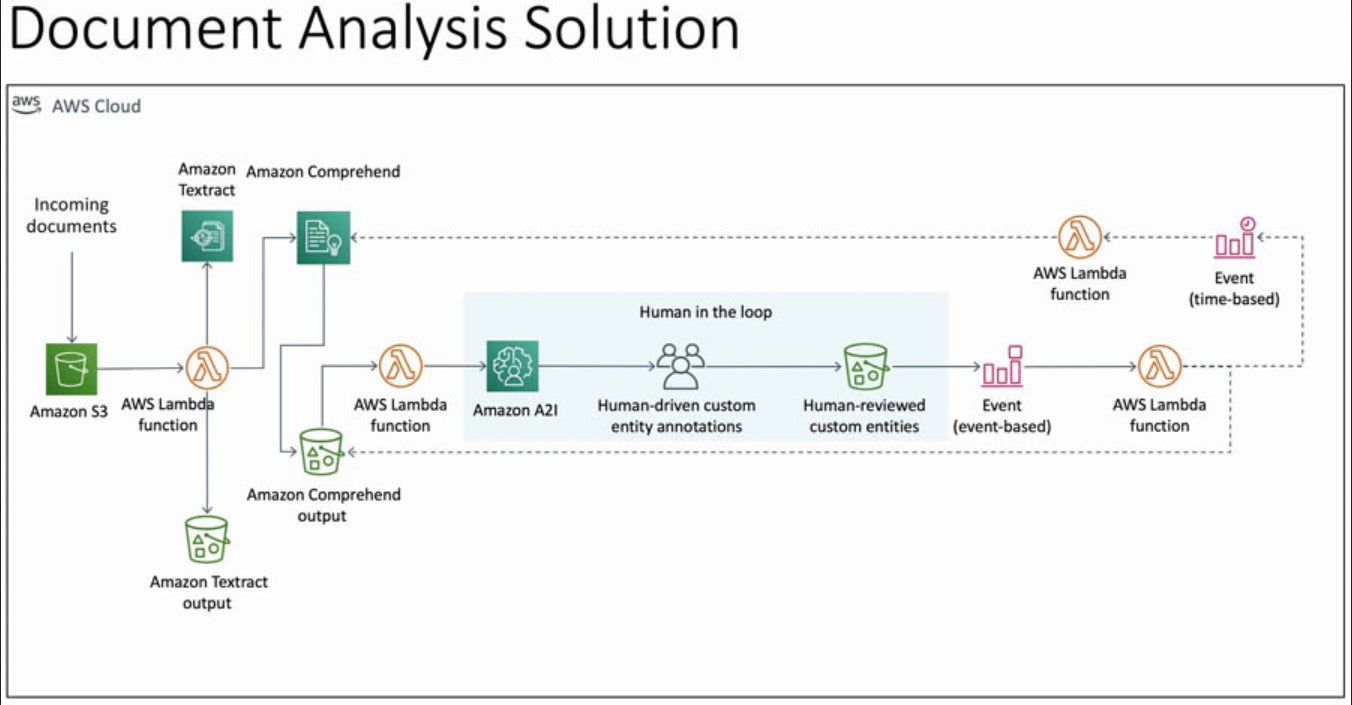 IDG
IDG
This shows a simplified diagram of the core of the AWS Document Understanding Solution. A more complete diagram (shown here and here) shows the web components and additional services such as queuing and database storage.
Azure Form Recognizer
Azure Form Recognizer applies advanced machine learning to accurately extract text, key-value pairs, tables, and structures from documents. With just six samples you can customize Azure Form Recognizer to understand your documents, both on-premises and in the cloud.
Microsoft Research has been investigating Document AI for several years. It released two benchmark datasets (for table recognition and page object detection) in 2019, and another two (for reading order detection and multi-lingual form understanding) more recently. It also released three multi-modal pre-training frameworks, which have been widely adopted for both first-party and third-party products and applications in Azure AI, such as Form Recognizer.
Two versions of Form Recognizer are currently available, v2.1 (GA) and v3.0 (preview). Form Recognizer v2.1 supports invoice, receipt, ID document, and business card models. Form Recognizer v3.0 adds a General Document model, a layout model, Form Recognizer Studio, and additional features in receipts, ID documents, and custom models.
Supported file formats include JPEG, PNG, BMP, TIFF, and PDF (text-embedded or scanned). Text-embedded PDFs are best to eliminate the possibility of error in character extraction and location. For PDF and TIFF, up to 2000 pages can be processed (with a free tier subscription, only the first two pages are processed). The file size must be less than 50 MB.
Form Recognizer supports seven handwritten natural languages and about 100 printed natural languages for layout and custom models, and just English for the other models. Form Recognizer APIs support up to seven programming language SDKs.
Azure Form Recognizer Studio (preview)
Azure Form Recognizer Studio is an online tool for visually exploring, understanding, and integrating features from the Form Recognizer service into your applications. The Studio makes learning the Form Recognizer service and setting up form processing much easier.
You can use the Form Recognizer Studio quickstart to get started analyzing documents with pre-trained models. You can also build custom form models and reference the models in your applications, using the Python SDK preview and other quickstarts. In addition, Form Recognizer Studio helps you with layout models and labeling.
Azure Form Recognizer general document model (preview)
The prebuilt general document model lets you extract key-value pairs and entities from documents without building a custom model. Its single API extracts key value pairs, entities, text, tables, and structure from documents. It supports structured, semi-structured, and unstructured data. Microsoft plans to periodically train the general document model on new data to improve its coverage and accuracy. The general document model should eliminate the need to build custom models for many common forms, and make Azure Form Recognizer more competitive with Google Document AI and Amazon Textract.
Azure Form Recognizer layout model
The Azure Form Recognizer Layout API extracts text, tables, selection marks, and structure information from documents and images. The layout model combines enhanced OCR capabilities with deep learning models to extract text, tables, selection marks, and document structure.
The layout model recognizes tables with few restrictions. It allows for merged cells, bordered and borderless layouts, and odd angles. It recognizes headers and selection marks (e.g. check boxes) and handles multiple colors. You can specify a reading order, which can handle multi-column layouts in Latin languages. The model can read handwritten text in Latin languages. You can specify which pages to use for text extraction.
The layout model supports seven handwritten natural languages and about 100 printed natural languages.
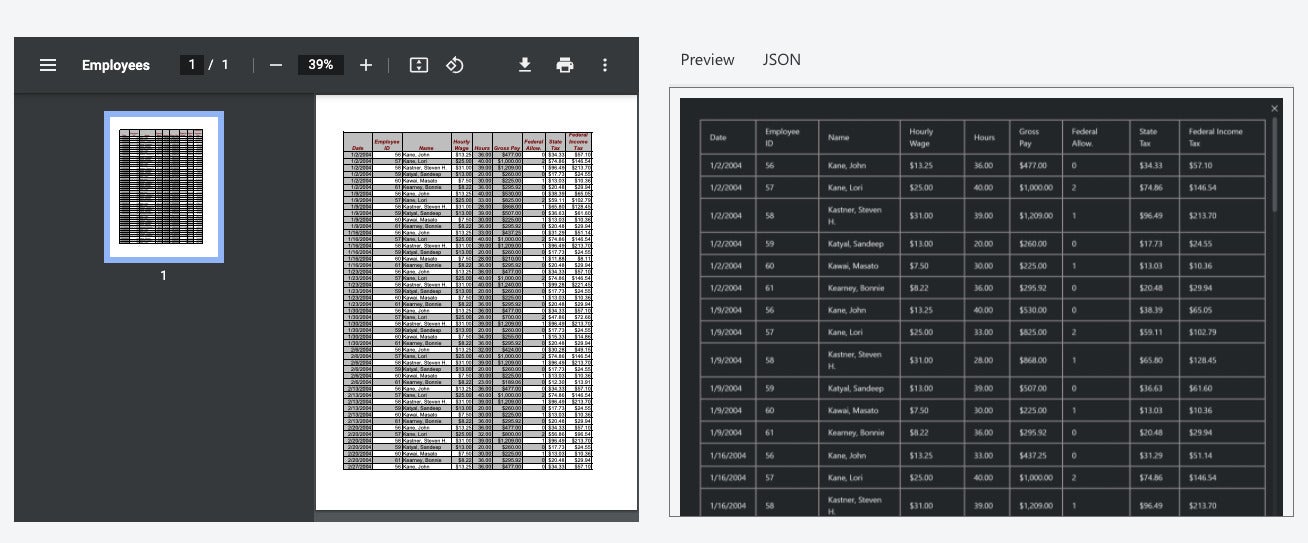 IDG
IDG
Employee table parsed with the layout model in Azure Form Recognizer.
Azure Form Recognizer invoice model
The Form Recognizer invoice model is a pre-built model for US English sales invoices that can parse phone-captured images, scanned documents, and digital PDFs. The invoice model knows about all the standard fields on invoices, as well as how to deal with line items.
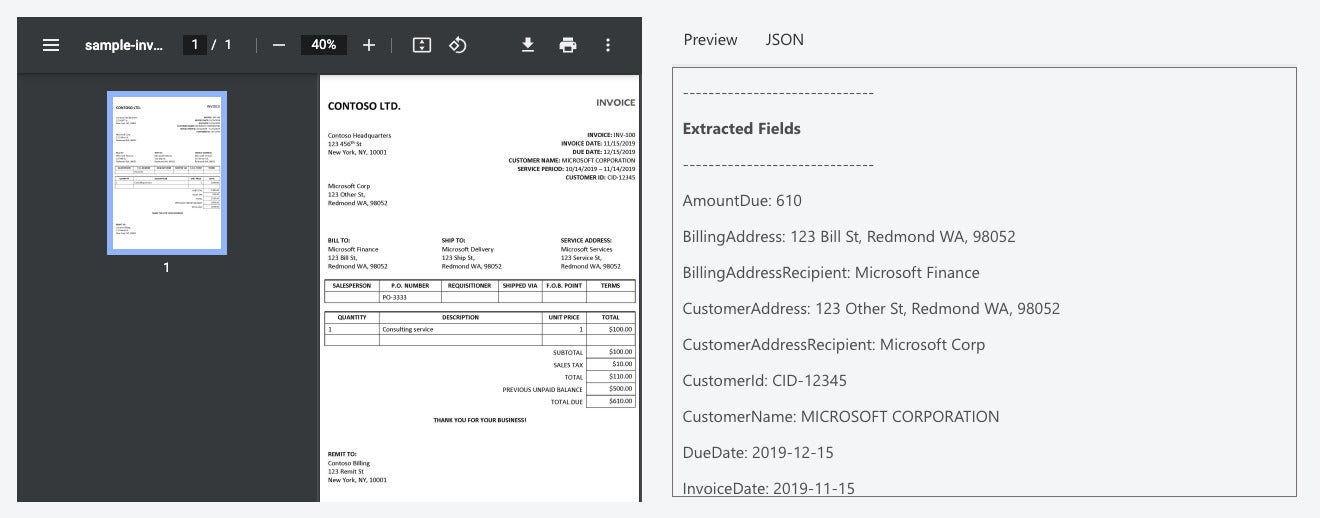 IDG
IDG
Invoice parsed with the invoice model in Azure Form Recognizer.
Azure Form Recognizer receipt model
The Form Recognizer receipt model extracts key information from sales receipts such as merchant name, merchant phone number, transaction date, tax, and transaction total. Receipts can be of various formats and quality including printed and handwritten receipts. This model supports US, UK, Australian, Canadian, and Indian English.
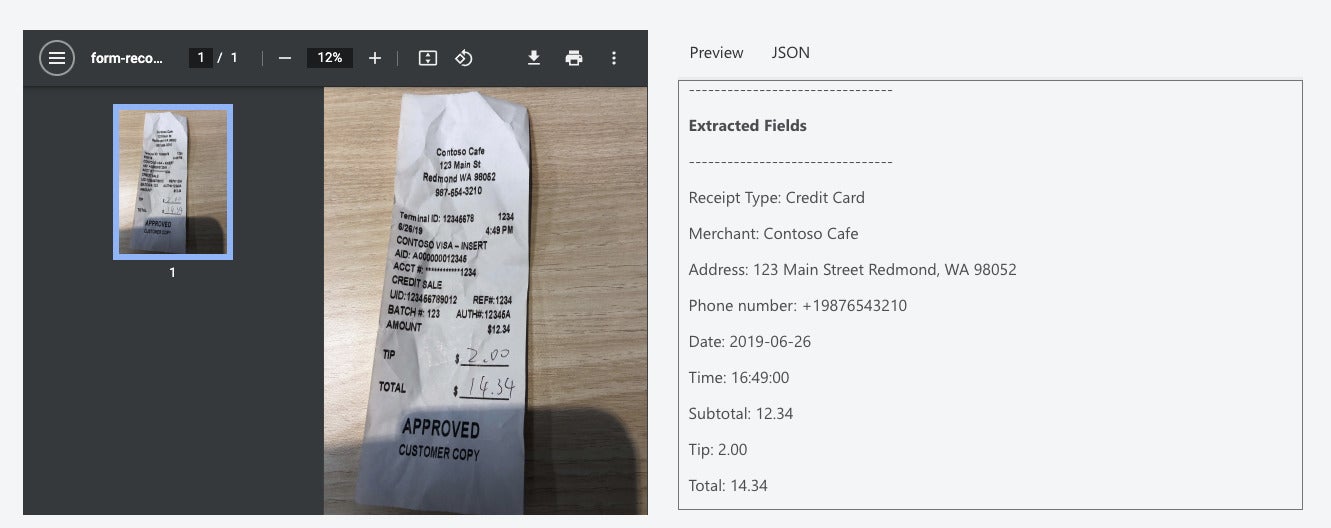 IDG
IDG
Receipt parsed with the receipt model in Azure Form Recognizer.
Azure Form Recognizer ID document model
The ID document model extracts key information from US driver’s licenses (all 50 states and District of Columbia) and international passport biographical pages (excluding visa and other travel documents). The API analyzes identity documents and extracts key information such as first name, last name, address, and date of birth.
 IDG
IDG
Driver’s license parsed with the ID model in Azure Form Recognizer.
Azure Form Recognizer business card model
The business card model extracts key information from business card images. The API extracts key information such as first name, last name, company name, email address, and phone number, and returns a structured JSON data representation. This model supports US, UK, Australian, Canadian, and Indian English.
Azure Form Recognizer custom and composed models
Form Recognizer custom models enable you to analyze and extract data from forms and documents specific to your business. Custom models are trained for your distinct data and use cases.
A composed model is created by taking a collection of custom models and assigning them to a single model that encompasses your form types. When a document is submitted to a composed model, the service performs a classification step to decide which custom model accurately represents the form presented for analysis.
You can train Form Recognizer custom models with as few as six exemplars of each form type, which takes the sting out of needing to train models for common forms such as those used for IRS reporting. Custom models support seven handwritten natural languages and about 100 printed natural languages. In addition, they can detect whether signatures are present, although they can’t check the signatures for validity.
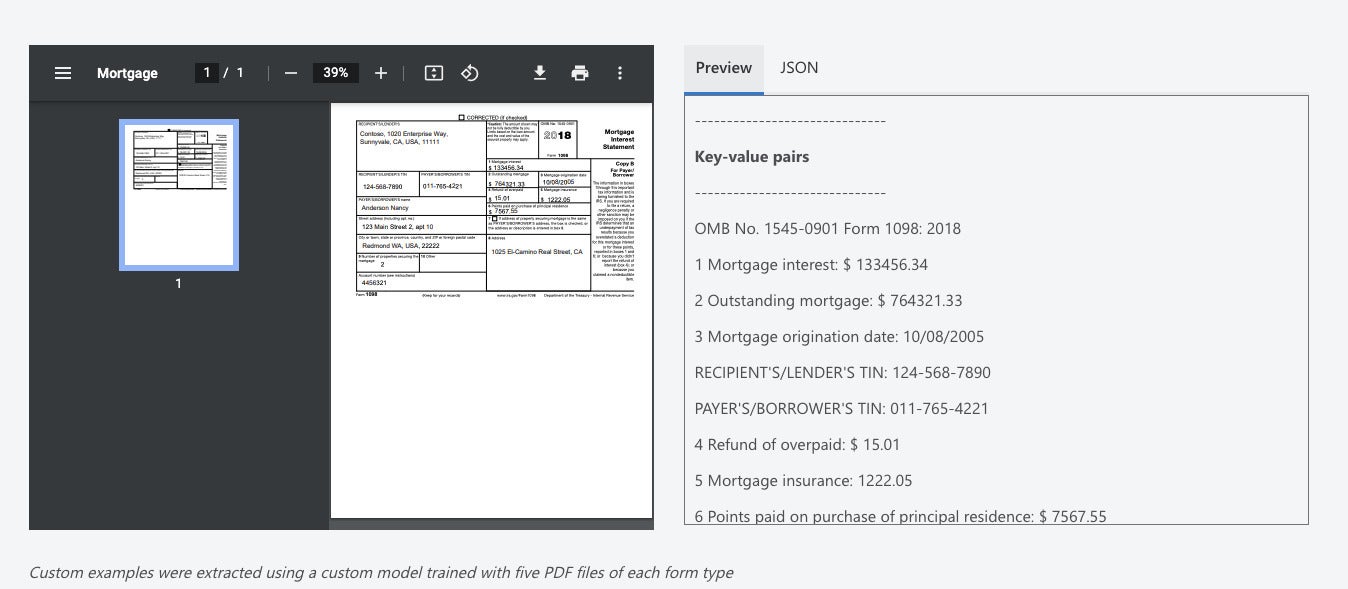 IDG
IDG
Mortgage reporting form 1098 parsed with a custom model, which was trained with five exemplars.
Google Cloud Document AI
Google Cloud Document AI (DocAI) includes general models as well as industry-specific models for contracts, lending, procurement, driver’s licenses, passports, and ID cards. It also supports human-in-the-loop (HITL) workflows to ensure accuracy when needed. DocAI became generally available in April 2021, although most of the services have limited access, which means that you need to apply to use them. Processing documents with an AutoML model is now deprecated.